Kaasaegses maailmas pole enam pea ühtegi valdkonda, kus infotehnoloogiat ei kasutataks – alustades tööstusest, meditsiinist, avalikust sektorist ja transpordist ning lõpetades omavahelise suhtlusega. Robotitel on meie igapäevaelus kasvav roll ja nii on üsna selge, et IT-spetsialistidel tulevikus tööd ja väljakutseid jagub ning vajadus nende järele kasvab kiiresti.
TalTechi IT-teaduskonna informaatika magistriprogrammi juht Juhan-Peep Ernitsa sõnutsi on õppekava mõeldud IT valdkonna bakalaureusekraadiga üliõpilastele, kes soovivad tehnilisi oskusi edasi arendada.
“Õppekavas moodustavad enamuse valikained, mille kaudu saab iga üliõpilane keskenduda just teda huvitavale teemavaldkonnale,” selgitab ta.
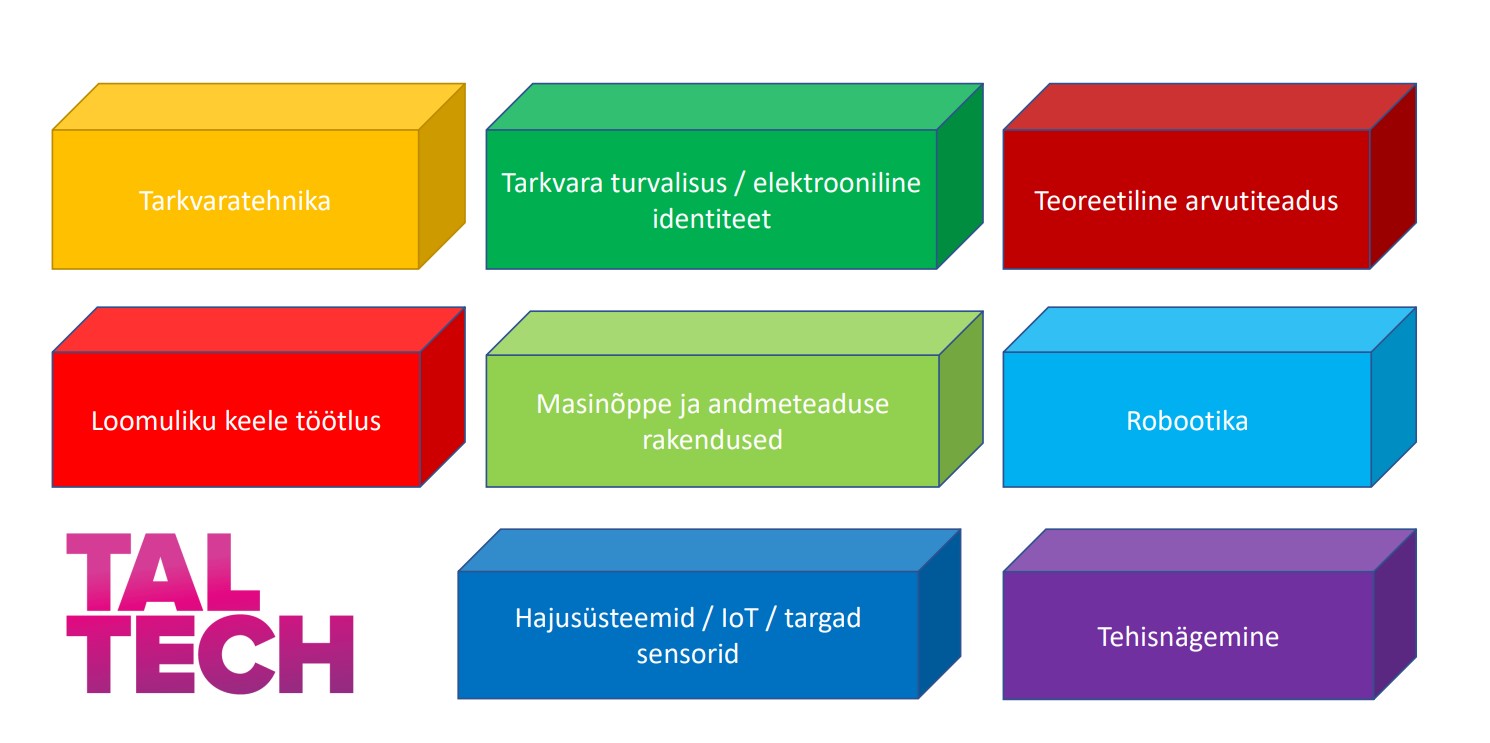
Järgneval joonisel on ülevaade viimastel aastatel informaatika magistris kaitstud magistritööde teemavaldkondadest:
Selleks, et saaks selgemaks, mida TalTechis informaatika magistriõppes õpitakse, selgitab Ernits kahe silmapaistva ja põneva magistritöö näitel.
Magistritöö keeletehnoloogiast: “Eestikeelse küsimus-vastus-süsteemi arendamine”
Selle magistritöö autor on Anu Käver, kes lõpetas magistriõpingud2021. aasta kevadel. Praegu töötab Käver tarkvarainsenerina ning on arendustiimi juht ühes fin-tech ettevõttes.
Anu Käveri magistritöö käsitles interneti otsimootoreid, juturoboteid ja erinevaid dialoogisüsteeme, mis püüavad elektroonilistest andmemassiividest leida inimese jaoks hetkel vajalikku informatsiooni. Arvestades seda, milline elektroonilise info üleküllus maailmas valitseb, on tegu vägagi päevakajalise valdkonnaga tehisintellekti arendamisel.
Infootsingu rakenduste aluseks on tihtipeale küsimus-vastus-süsteemid. Käver arendas magistritöös välja esimese eestikeelse küsimus-vastus-süsteemi. Süsteem töötab nii, et saab ette lõigu eestikeelset teksti, mis on ühe inimese poolt loomulikus keelepruugis esitatud küsimus. Seejärel peab süsteem leidma tekstist lühima lõigu, mis sisaldab vastust küsimusele.
Toome näite. Tekstilõik: Politseinikud kontrollisid 29. mai õhtul Tallinna ringteel liiklusõnnetusse sattunud BMW sõiduautot. Sõiduki juht ja reisija õnnetuses viga ei saanud, kuid politseinikel oli alust arvata, et mõlemad mehed võisid olla narkojoobes.
Küsimus: Kus tegi narkouimas juht avarii?
Süsteemi leitud vastus: Tallinna ringteel.
Väljakutse: kuidas süsteemile eesti keel selgeks õpetada?
Suurimaks väljakutseks kõige selle juures oli asjaolu, et edukamad tänapäevased küsimus-vastus-süsteemid treenitakse masinõppe abil ja see nõuab väga suuri treeningandmestikke. Näiteks koosneb kõige populaarsem ingliskeelne küsimus-vastus-andmestik SQuAD ligi 150 tuhandest andmeühikust (tekstilõik+küsimus+vastus). Eesti keeles sellised andmestikud aga puuduvad.
Probleemile tuli läheneda kahest nurgast. Esiteks koostas Anu ise Vikipeedia artiklite põhja algupärase 1115 küsimusega eestikeelse treeningandmestiku. Teiseks üritas ta ära kasutada ülekandeõpet (transfer learning) ehk kasutas ingliskeelset SQuADi andmestikku eestikeelse süsteemi treenimiseks. Mõne eksperimendi jaoks tuli kogu SQuADi masintõlke abil eesti keelde tõlkida.
Anu proovis ka vastupidist – tõlkis enda koostatud andmestiku, mida ta kasutas nii treenimisel kui tulemuste valideerimisel, inglise keelde. Leitud vastus tuli seejärel eesti keelde tagasi tõlkida.
Neid meetodeid omavahel kombineerides treenis ta mudeleid järgemööda eesti ja inglise keeles või liitis andmestikud kokku. Kombineerimist võimaldas suurte universaalsete keelemudelite kasutamine töö aluskomponendina. Kaks neist, XLM-RoBERTa ning mitmekeelne BERT, modelleerivad korraga sajakonna eri keele sõnavara ühtses vektorruumis. Selline mudel suudab mitut keelt korraga “mõista”, kuid teda tuli edasi treenida konkreetset ülesannet täitma – küsimustele vastama. Ainult eestikeelsete eksperimentide puhul oli kasutusel ka eesti keele mudel EstBERT .
Parimas eksperimendis oli õige vastuse leidmise täpsus (F1-skoor) 82,4 protsenti. Kuna parima mudeli aluseks on mitmekeelne keelemudel, töötab süsteem tegelikult paljudes keeltes, täpsus on siiski suurim eesti ja inglise keeles.
Magistritöö robootikast: “Pime kaardistamine ja lokaliseerimine väikesemõõdulistele kaevandusrobotitele”
Andreas Nagel, kes kaitses oma magistritöö 2021. aasta kevadel, töötab praegu ühes robotite väljatöötamisega seotud ettevõttes tarkvaraarendajana.
Tema asus informaatika magistrikraadi omandama pärast arvutisüsteemide bakalaureuse õppekava lõpetamist. Informaatika magistriõpingute käigus sai ta aru, et tema huvi on tegeleda robootikaga, täpsemalt robotite tarkvaraga. Robotitele tarkvara arendamine eeldab tervikliku süsteemi mõistmist, samuti teadmisi tõenäosusteooriast ja füüsikast.
Magistritöö kirjutamise käigus lõi ta tipptasemel samaaegse kaardistamise ja lokaliseerimise raamistiku, et anda TalTechis loodud ümbruse kaardistamise ja enese lokaliseerimise võimekus loodust imiteerivale vurrudepõhisele sensorvõrgustikule.
Lihtsamalt öeldes – tehti esimene samm, et panna robotid näriliste viisil vurrude abil pimedas orienteeruma. Üheks sellise navigeerimismeetodi rakenduseks võiks olla näiteks kaevanduskäikude kaardistamine mahajäetud kaevandustes, kus inimestel võib olla ohtlik liikuda.
Miks robotite tarkvara arendamine on oluline teema?
Autonoomsed robotid ilmuvad järk-järgult meie igapäevaellu: metsaistutus-, lumekoristus-, pakirobotid ning isesõitvad autod arendatakse iga aastaga üha paremaks ja targemaks. Ühel hetkel toimub läbimurre nende autonoomse tegutsemise ning otsustamise võimekuses ja nad saavad osaks meie igapäevast. Seepärast tulebki olla veendunud, et tehisintellekt ei teeks vahel „rumalaid” otsuseid ning oleks usaldusväärne. Eriti oluline on usaldusväärsus kriitilistes valdkondades, nagu meditsiin, transport, kõikvõimalikud riiklikud süsteemid ja andmed, kaitsevaldkond jne.
TalTechi infotehnoloogia teaduskonnas tegeletakse just sellega, et tehisintellekti rakendataks hästi läbimõeldult, eetiliselt, (küber)turvaliselt ja usaldusväärselt. Pea kõik infotehnoloogia teaduskonna magistrikavad käsitlevad tehisintellekti ja selle arendamist, kuid just informaatika magistrikaval saab spetsialiseeruda tehisintellekti rakenduste väljatöötamisele.
Sisseastumisinfo leiad siit. Avaldusi saab esitada juba praegu ja seda 6. juuli keskpäevani.